[ニュースの個別化推薦]"Compute Document Similarity Using Autoencoder With Triplet Loss"を読んで真似してみる...!① 理論とサンプルデータの前処理
はじめに
私は先日、ニュースのようなテキスト情報を持つアイテムの推薦システムに関して調べていたのですが、そこで、yahooの方から出ている論文"Embedding-based News Recommendation for Millions of Users"(元論文link)に出会いました。
その論文では、「ニュースの個別化推薦では、推薦候補となる記事は直ぐに期限切れとなり、短いスパンで新しい記事に入れ替わる。従って、Matrix Factorizationを始めとした単にユーザやアイテムをidとして扱う協調フィルタリング系手法はニュース推薦には適さない。」と主張し、Denoising Autoencoderを用いてニュース記事を埋め込みベクトルとして表現して、その記事埋め込みベクトルを用いて、ああだこうだしていました。
新規手法の提案のようでありながらも、オフライン評価だけでなく実サービスに導入してオンライン評価もしているようです。 また、Yahooの巨大な実サービスに耐えうる推薦システムである為に、スケーラビリティ問題を考慮した手法となっている、っぽいです...! 遅ればせながら最近、「オンライン学習」の重要性に気づいた私からすると、非常に興味深い、魅力的な論文なわけです。
ただ残念ながら、まずDenoising Autoencoderが分からない私にとっては、まさに「なんのこっちゃ?」案件です。 なので、"Embedding-based News Recommendation for Millions of Users"を読む為の前準備として、"Compute Document Similarity Using Autoencoder With Triplet Loss"を読んでDenoising Autoencoderによるテキストの埋め込みベクトル生成に関して理解を深めます...! これが本記事の目的になります。
導入
文書の類似度を計算する最も一般的な方法は、文書をTF-IDFベクトルに変換し、これらのベクトルにコサイン類似度などの任意の類似度指標を適用することです。
ここで「TF-IDFベクトルに変換」というのは、文書集合(コーパス)$D$における文書$d$の単語$t$の$tfidf(t, d, D) = tf(t, d) \cdot idf(t, D)$(スカラー)を、文書毎に繋いでベクトル化したもの、と認識してます。
しかしこのアプローチは、2つの欠点/制限があるようです。
- すべての文書を大きな次元(〜10k)(= つまり文書内のtoken数???)のベクトルに変換する必要がある。これらのベクトルが疎である場合でも、ニュース領域で見られるような厳しい時間制約の中で、これらの高次元ベクトル間の類似性を計算することは適切でないかもしれない。
- 類似した、あるいは全く同じ出来事について書かれたニュース記事に対しては、このアプローチは高い類似度値を与える。しかし、同じカテゴリの記事で異なる出来事について話している場合は、共通のキーワードが存在しないため、類似度がゼロに近くなる可能性がある。
個人的には2つ目の欠点が特に重要な気がしました...! 例えば、サッカーに関するニュース記事$A$とニュース記事$B$では、同じサッカー用語が使われていたりしますよね。なので2つのtf-idfベクトルの類似度は高くなります。しかし更に、野球に関するニュース記事$C$と自民党に関するニュース記事$D$がある場合、tf-idfベクトルでは必ずしも$\text{simularity}(A, C) > \text{simularity}(A, D)$として表現できない可能性がある、$\text{simularity}(A, C) \leq \text{simularity}(A, D)$のようなベクトルになってしまうかもしれない...!という事ですね。 (理想的には、$\text{simularity}(A, B) > \text{simularity}(A, C) > \text{simularity}(A, D)$として表現できるようなベクトルを生成したい...!)
そこで本論文の手法では、以下の手法で↑の制限の解決を試みています。
- Denoising Autoencoderを用いることで、高次元のTF-IDFベクトルを低次元の埋め込みに圧縮することができる。
- Triplet Loss functionを用いることで、文書間のカテゴリカルな類似性を保持することができる。(上の例における、サッカーの記事$A$と野球の記事$C$の類似性を表現したい...!)
次のセクション以降で、Denoising AutoencoderとTriplet loss functionを別々にまとめていきます。
Denoising Autoencoderに関して
Autoencoderは、基本的に教師なし学習を行うニューラルネットワークで、圧縮された埋め込みデータ(decoder)から入力ベクトル(encoder)を再構成しようとするものです。
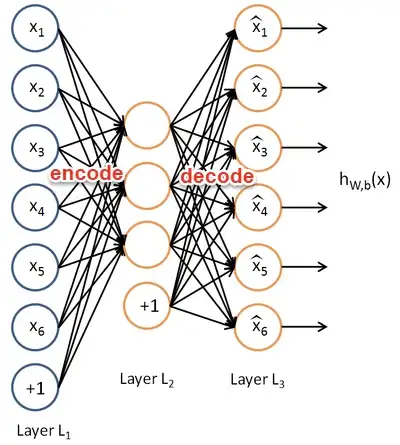
上の図においては、L1層が入力ベクトル、隠れ層L2が埋め込み、L3層が再構成された入力となります。通常、L1->L2の処理はencoder、L2->L3の処理はdecoderと呼ばれます。
Autoencoderは、エンコード時にノイズを除去して有用な情報だけを残し、デコーダーが圧縮された情報を使って入力を完全に復元することができるという考え方です。
そして、Denoising(ノイズ除去) Autoencoderは、学習段階で入力要素のある割合をゼロにすることで、確率的に入力を破損します。 これは,入力の小さな変化に対して埋め込みをより頑健にすることがモチベーションになっています。
以下が一般的なDenoising Autoencoderの数式です。
$$ \tilde{x} \sim C(\tilde{x}|x) \ h = f(W\tilde{x} + b) \ y = f(W'h + b') \ \theta = \argmin{W, W', b, b'} \sum{x \in X} L(y, x) $$
ここで、
- $x \in X$はオリジナルの入力ベクトル
- $f$はactivate function(活性化関数)
- $L$はloss function(損失関数)
- $C$はcorrupting distribution(破損関数...?).
- $W, b$は入力層->隠れ層の重みとバイアス, $W', b'$は隠れ層->出力層の重みとバイアス。これらは学習されるべきパラメータです。
- $\theta$: 損失関数の最小化によって最適化されたパラメータ群。
損失関数は、通常、squared loss(誤差平方和)またはcross-entropyが使用されます。
Triplet Lossに関して
Triplet lossはFaceNetで初めて使用された手法であり、A Unified Embedding for Face Recognition and Clustering by Googleにて顔の埋め込みを学習するのに使われたそうです。
Triplet lossの場合、学習段階で3つの入力が必要です。
- Anchor(メインの学習対象となるデータの事っぽい...! )
- Positive(メインの画像と同じラベルを持つデータ)
- Negative(メインの画像と異なるラベルを持つデータ)

学習中、Triplet lossはアンカーとポジティブの間の距離を最小化(類似性を最大化)し、アンカーとネガティブの間の距離を最大化(類似性を最小化)するように学習をコントロールします。

上図はFaceNetの例ですが、同一人物の画像は埋め込みベクトル間のユークリッド距離が小さくなっています.(i.e. ベクトル間の類似度が高い) このことから、学習で得られた埋め込みベクトルは、元画像の距離・類似性情報を保持していることが分かります。
そしてYahoo! JAPANでは、FaceNetで用いられている損失関数とは異なるものの、同様の考え方をニュース記事の埋め込みベクトルに適用し、カテゴリの類似性を保持するようにした、との事です。
Denoising AutoencoderとTriplet Lossを組み合わせる
Article De-duplication Using Distributed Representationsで紹介したアプローチは、triplet lossを伴うDenoising Autoencoderを用いて、カテゴリカルな類似性を保持した埋め込みベクトルを生成するものです。
Binary word count vector is used as input to the DAE, and for every news article (anchor), we need another news article that has the same category label (positive) and another news article that has different category label (negative). DAEの入力としてBinary word count vector(2値語数ベクトル)を用います。1つのニュース記事(アンカー)に対して、同じカテゴリラベル(ポジティブ)を持つ別のニュース記事と、異なるカテゴリラベル(ネガティブ)を持つ別のニュース記事が必要です。
数式の表記
- (アンカー, 正, 負)の入力ベクトル($x_1$, $x_2$, $x_3$)とする。
- (アンカー, 正, 負)の埋め込みベクトル(= Autoencoderにおけるhidden layerベクトル)は($h_1$, $h_2$, $h_3$)とする。
Loss function
$x_1$は$x_3$よりも$x_2$に類似しているので、カテゴリカルな類似性を保持するために、$\text{sim}(h_1, h_2) > \text{sim}(h_1, h_3) = h_1T h_2 > h_1T h_3$としたい...! 従ってそれを表現する為に、Denoising Autoencoderの損失関数をtriplet lossを用いて以下のようにアップデートします。
$$ h_n = f(W \tilde{x}_n + b) - f(b) \tag{1} $$
$$ \phi(h_1,h_2, h_3) = \log(1 + \exp (h_1T h_3 - h_1T h_2)) \tag{2} $$
$$ \theta = \argmin{W, W', b, b'} \sum{(x_1,x_2,x_3)\in T} \sum_{n=1}^3 L(y_n,x_n) + \alpha \phi(h_1, h_2, h_3) \ \text{Triplet Loss function of autoencoder} $$
式(1)より、ある埋め込みベクトル$h_n$は、入力ベクトルがゼロ($x=0$)なら埋め込みベクトルもゼロになる($h_n = f(b) - f(b) = 0$)の性質を満たします。 ここで、本タスクにおいて$x$はtf-idfベクトルなので、$x=0$とは「ある記事が他の記事達と比べてユニークな & 利用可能な情報を持っていないこと」を意味します。

式(2)より、$\phi$は記事の類似性に関するpenalty function(ペナルティ関数)です。上の曲線から、$\phi$を最小化することは即ち、$h1T h2 > h1T h3$の傾向をより大きくする事を意味します。
なお学習全体の目的は、$\phi$を最小化するだけでなく、$L$と$\phi$の両方最小化することであることです。 $L$がなければ、ネットワークは重みがゼロになり、全ての記事に対して埋め込みベクトル$h = 0$になる可能性があります。 したがって、
学習後、埋め込みベクトルにコサイン類似度を適用することで、2つの記事がどの程度似ているかを評価します。
Triplet Mining
上で述べたように、Triplet Lossを用いたDenoising Autoencoderを学習するためには、学習データとしてTriplet(アンカー、正、負)のセットを用意する必要があります。つまり、アンカーごとに、ポジティブとネガティブをマッピングする必要があります。 これを手作業で行うとなると、なかなか大変そうです。
実は↑の作業は、Triplet Miningという手法?で自動的にマッピングできるようです...(?)
With triplet mining, we only need to provide anchor and label of the anchor to DAE during training. And it will find out all possible triplets by constructing a 3-dimensional matrix. A much more detailed explanation and Tensorflow implementation could be find here. Triplet Miningでは、学習時にアンカーとアンカーのラベルをDenoising Autoencoderに与えるだけでよい。 そして、3次元の行列を構築することで、可能性のあるTripletを全て探し出すことができる。 より詳細な説明とTensorflowの実装はこちらに記述されているようなので、あとで読むかー...
実装の準備:
上の説明を読んでいたら実際に動かしてみたくなったので、"Compute Document Similarity Using Autoencoder With Triplet Loss"の実験を真似しながら、サンプルデータを使ってDenoising Autoencoder × triplet lossによるテキストの埋め込みベクトル生成を試してみます...!
サンプルデータの取得
サンプルデータとして、kaggleのhogehogeを使用します。 このデータセットはcategoryラベルとstoryラベルを持つ10348のニュース記事を含んでいます。
以下は、データセット内の各カラムの概要です。
- id: 記事のユニークid
- title: 記事のtitle
- url: 記事のurl
- publisher: 執筆者
- category:ニュースアイテムののカテゴリ。 次のいずれか.(-- b : ビジネス -- t : 科学技術 -- e : エンターテイメント -- m : 健康)
- story: 記事で取り上げるニュース内容のID(英数字)
- hostname: 記事を投稿したホスト名(?)
- timestamp: 記事の公開日時
- main_content: 記事のテキスト
- main_content_len: 記事のテキストの長さ
ここで、categoryラベルはニュース記事の大きめな分類ですかね。サッカー記事・野球記事・自民党記事の例で言えば、"スポーツ"や"政治"などの分類をイメージしています。 tf-idfベクトルのアプローチでは、上手く類似性を表現できない可能性があるという方ですね。
また、storyラベルはニュース記事のより細かい分類ですね。 サッカー記事・野球記事・自民党記事の例で言えば、"サッカー"や"野球"などのより細かい記事内容の分類のイメージです。(もっと"ワールドカップ2022"とか"セパ交流戦"とか、より細かい分類かもしれません...!) このスケールの分類では、同ラベルの記事群におそらく同じ単語が出現する傾向にあるので、tf-idfベクトルが得意な解像度のラベルなのかな...?
サンプルデータの整形
整形とは言っても、単にデータセットを読み込んで、categoryラベルとstoryラベルを通し番号化(label encoding?)するだけです:)
STORY_COL = "story" CATEGORY_COL = "category" def get_valid_story_label(article_df: pd.DataFrame) -> Tuple[pd.DataFrame, Dict[int, str]]: """get valid story(テキストのより細かい分類ラベル, 同一の用語が頻繁に出現する)""" story_value_counts = article_df[STORY_COL].value_counts() story_indices = article_df[STORY_COL].isin( values=story_value_counts[story_value_counts > 0].index, ) article_df["label_story_valid"] = 0 article_df.loc[story_indices, "label_story_valid"] = 1 article_df["label_story"], label_list = pd.factorize(article_df[STORY_COL]) # カテゴリをintにencode label_idx_mapping = {idx: label for idx, label in enumerate(label_list)} return article_df, label_idx_mapping def get_valid_category_label(article_df: pd.DataFrame) -> Tuple[pd.DataFrame, Dict[int, str]]: """get valid category(テキストのよりラフな分類ラベル, 同一の用語が必ずしも頻繁に出現するとは限らない)""" category_value_counts = article_df[CATEGORY_COL].value_counts() category_indices = article_df[CATEGORY_COL].isin( values=category_value_counts[category_value_counts > 0].index, ) article_df[f"label_category_valid"] = 0 article_df.loc[category_indices, "label_category_valid"] = 1 article_df["label_category"], label_list = pd.factorize(article_df[CATEGORY_COL]) # カテゴリをintにencode label_idx_mapping = {idx: label for idx, label in enumerate(label_list)} return article_df, label_idx_mapping def main(): article_df = pd.read_parquet("uci_news_data.parquetのファイルパス") article_df = article_df.sort_values(by="id") # article idの昇順でソート article_df, label_idx_story_mapping = get_valid_story_label(article_df) article_df, label_idx_category_mapping = get_valid_category_label(article_df) print(article_df) # テキスト(article_df[main_contents])をtokenize # Scikit learn’s Count Vectorizerにより、tonenizeされたテキストをbinary ベクトル化 # denoizing autoencoder による学習(anchorのテキストとラベルを渡せば良い) if __name__ == "__main__": main()
このような感じで2種類の解像度のカテゴリラベルのカラムを生成できました! 次回から、Denosing Autoencoder × triplet lossの実装に入ります...!!